本书对于编程知识零基础的办公人士特别友好,其摒弃了晦涩的理论讲解,引入了实用的办公场景,为办公人士开辟了一条学习办公自动化的新路。本书精选典型办公案例以及通俗易懂的讲解,有助于办公人士掌握Python+Word+Excel+PPT+PDF的使用,以及对网络数据爬虫进行入门,也有利于读者在办公自动化和大数据的应用上能够更进一步。本书代码简洁、思路清晰,在学习过程中只需简单地修改一下本书附赠代码就能够应用到实际的工作场景中,让学习和工作事半功倍。
本书是一本案例驱动型的Python编程指南,将语法知识和编程思路融入大量的典型案例,带领读者一步步学会将Python打造成自动化办公的利器。
全书共10章,可划分为4个部分。第1部分包括第1章和第2章,主要讲解Python编程环境的搭建方法和Python的基础语法知识。第2部分包括第3~7章,通过大量案例讲解如何用Python自动化处理计算机文件、PDF文件和Office文件。第3部分包括第8章和第9章,主要讲解如何利用Python编写爬虫程序,自动从网页上爬取数据。第4部分为第10章,主要讲解如何利用Python自动发送电子邮件。
本书案例典型实用,讲解浅显易懂,适合具备一定的Office软件操作基础又想进一步提高工作效率的办公人员,如从事文秘、行政、人事、营销、财务等职业的人士阅读,也可供Python编程初学者参考。
第1章 Python快速上手1.1 Python编程环境的搭建
1.1.1 安装与配置Anaconda
1.1.2 安装与配置PyCharm
1.2 Python的模块
1.2.1 初识模块
1.2.2 模块的安装
1.3 常见问题和解决办法
第2章 Python的基础语法知识
2.1 变量
2.2 数据类型:数字与字符串
2.2.1 数字
2.2.2 字符串
2.2.3 数据类型的查询
2.2.4 数据类型的转换
2.3 数据类型:列表、字典、元组与集合
2.3.1 列表
2.3.2 字典
2.3.3 元组和集合
2.4 运算符
2.4.1 算术运算符和字符串运算符
2.4.2 比较运算符
2.4.3 赋值运算符
2.4.4 逻辑运算符
2.5 编码基本规范
2.5.1 缩进
2.5.2 注释
2.6 控制语句
2.6.1 if语句
2.6.2 for语句
2.6.3 while语句
2.6.4 控制语句的嵌套
2.7 函数
2.7.1 内置函数
2.7.2 自定义函数
2.8 模块的导入
2.8.1 import语句导入法
2.8.2 from语句导入法
第3章 自动化整理计算机文件
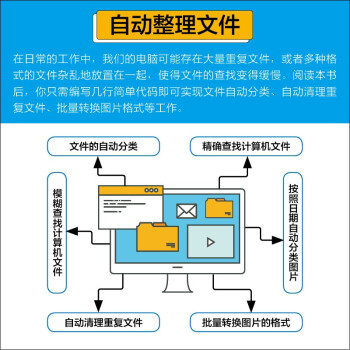
3.1 文件的自动分类
3.2 文件和文件夹的快速查找
3.3 自动清理重复文件
3.4 批量转换图片的格式
3.5 按照日期自动分类图片
第4章 自动化处理PDF文件
4.1 批量下载PDF文件
4.1.1 使用Selenium模块爬取多页内容
4.1.2 使用Selenium模块批量下载PDF文件
4.2 批量合并PDF文件
4.3 批量拆分PDF文件
4.4 批量加密PDF文件
4.5 批量为PDF文件添加水印
4.5.1 自定义函数创建水印文件
4.5.2 自定义函数添加水印
4.5.3 使用循环为每个PDF文件添加水印
第5章 自动化处理Word文档
5.1 批量生成Word合同
5.1.1 读取文件并进行查找和替换
5.1.2 使用循环套用模板生成合同
5.2 将Word文档批量转换为PDF文件
5.3 在Word文档中批量标记关键词
5.4 在Word文档中批量替换关键词
第6章 自动化处理Excel工作簿
6.1 批量生成产品出货清单
6.1.1 提取出货统计表中的数据
6.1.2 使用for语句创建产品出货清单
6.2 批量替换工作簿的单元格数据
6.3 将多个工作表合并为一个工作表
6.3.1 使用xlwings模块读取多个工作表中的数据
6.3.2 新建工作簿存放合并后的数据
6.4 将一个工作表拆分为多个工作簿
6.5 批量拆分列数据
6.6 批量分类汇总数据
第7章 自动化处理PowerPoint演示文稿
7.1 批量提取演示文稿中的文本内容
7.2 将演示文稿批量导出为图片和PDF文件
7.3 自动读取图文素材制作演示文稿
7.4 批量提取演示文稿中的图片素材
第8章 爬虫技术基础
8.1 认识网页结构
8.1.1 查看网页的源代码
8.1.2 初步了解网页结构
8.1.3 网页结构的组成
8.1.4 百度新闻页面结构剖析
8.2 Requests模块
8.3 正则表达式
8.3.1 正则表达式基础知识
8.3.2 使用正则表达式提取数据
8.4 Selenium模块
8.4.1 网页数据爬取的难点
8.4.2 浏览器驱动程序的下载与安装
8.4.3 使用Selenium模块获取网页真正的源代码
8.4.4 使用Selenium模块模拟鼠标和键盘操作
第9章 爬虫实战演练
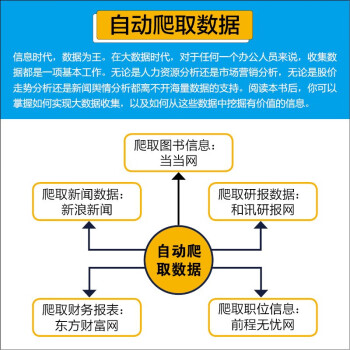
9.1 爬取图书数据—当当网
9.1.1 使用Requests模块获取网页源代码
9.1.2 编写正则表达式提取图书数据
9.1.3 批量爬取多页数据
9.2 爬取新闻数据—新浪新闻
9.2.1 使用Selenium模块获取网页源代码
9.2.2 编写正则表达式提取新闻数据
9.2.3 自定义函数完成多个关键词的批量爬取
9.3 爬取价格数据—农业农村部网站
9.3.1 使用Selenium模块获取网页源代码
9.3.2 使用pandas模块获取网页中的表格数据
9.3.3 批量爬取多页数据
9.4 爬取职位数据—前程无忧网
9.4.1 使用Selenium模块搜索职位
9.4.2 编写正则表达式提取数据并保存
9.4.3 批量爬取多页数据
9.5 爬取财务报表—东方财富网
9.5.1 使用Selenium模块爬取单页财务报表
9.5.2 使用Selenium模块爬取多页财务报表
9.5.3 爬取指定时期和指定种类的财务数据
第10章 自动化处理电子邮件
10.1 自动发送电子邮件
10.1.1 获取SMTP授权码
10.1.2 自动发送文本格式的电子邮件
10.1.3 自动发送HTML格式的电子邮件
10.1.4 自动发送带附件的电子邮件
10.2 批量发送电子邮件
10.3 定时发送电子邮件
10.3.1 自动爬取数据并通过电子邮件发送
10.3.2 利用while True循环实现定时发送电子邮件
10.3.3 利用Schedule模块实现定时发送电子邮件