
基于K8s 1.18,囊括所有K8s新特性和应用。
最权威:
由Kubernetes不同领域的专家共同执笔,全方位深入解读技术细节。
最实用:
五年多互联网行业Kubernetes生产化实践经验分享,助你不再踩坑。
最全视角:
深入剖析Kubernetes架构决策及设计原理。
从长期运维的角度,解析如何构建和运维生产化集群并持续优化。
分享大规模集群、多集群的运维挑战。
基于多租户Kubernetes的应用容器化、高可用部署和多活数据中心流量管理进行案例分享。
Kubernetes是由谷歌主导的基于容器技术的集群管理系统,其设计理念多数衍生自谷歌内部的集群管理系统的设计和运维经验。本书从设计层面剖析了Kubernetes的设计原理,并阐述了其设计背后的生产系统问题。Kubernetes作为开放式平台,具有对不同类型的应用(有状态应用或无状态应用,在线服务或离线任务)进行统一管控的能力。本书从互联网公司的视角出发,分享了如何构建高可用的多租户集群,如何确保集群的稳定性和高性能。此外,本书阐述了数据面优化的重要性,并介绍了各个关键点,以确保使用物理机或虚拟机的应用在迁移至容器平台后能够获得最佳性能。
本书的适读对象包括Kubernetes架构师、运维人员、测试工程师、技术经理,以及寻求应用落地方案的软件架构师和开发人员。另外,本书苛求于生产系统最佳实践,对于已有Kubernetes基础的读者,阅读本书会有事半功倍的效果。
1.2.4 控制器模式
声明式系统的工作原理是什么?当用户定义对象的期望状态时,Kubernetes通过何种机制确保实际状态与期望状态最终保持一致?在定义了如此多的对象后,这些对象又是如何联动起来,完成一个个业务流的呢?秘密就是控制器模式,Kubernetes定义了一系列的控制器,事实上几乎所有的Kubernetes对象都被一个或数个控制器所监听,当对象发生变化时,控制器会捕获对象变化并完成配置操作。
Kubernetes的功能组件会在后面章节中展开,但本节深入理解控制器模式有助于理解Kubernetes的运作机制。API Server是Kubernetes的大脑,保存了所有对象及其状态。开源项目client-go对控制器的编写提供了完备的自动化支持,任何Kubernetes对象都可以由client-go创建供控制器使用的Informer()和Lister()接口。如图1-6所示,控制器的工作流程就是围绕着Informer()和Lister()的。
Informer()用于接收资源对象的变化的Event,针对Add、Update和Delete的事件,可以注册相应的EventHandler。在EventHandler内,根据传入的object调用controller.KeyFunc计算出字符串key,并把它加入控制器的队列中。
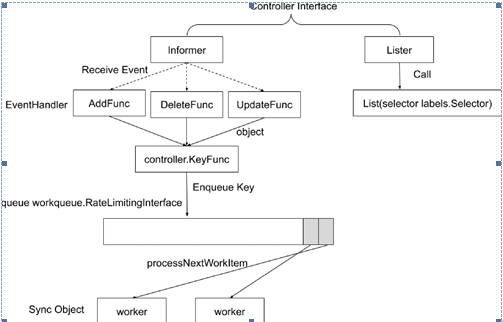
图1-6 控制器的工作流程
Lister()是给控制器提供主动查询资源对象的接口,我们根据labels.Selector来指定筛选条件。
控制器模式是一个标准的生产者-消费者模式。一方面,控制器在启动后,Informer会监听其所关注的对象变化。一旦对象发生了创建、更新和删除等事件,这些事件会由核心组件API Server推送给控制器。控制器会将对象保存在本地缓存中,并将对象的主键推送至消息队列,此为生产者。
另一方面,控制器会启动多个工作子线程(Worker),从队列中依次获取对象主键,并从缓存中读取完整状态,按照期望状态完成配置更改,并将最终状态回写至API Server,此为消费者。
Kubernetes就是基于此模式保证了整个系统的最终一致性。
Kubernetes运行一组控制器,以使资源的当前状态与所需状态保持匹配。对于基于事件的体系结构,控制器利用事件去触发相应的自定义代码,这部分都是由SharedInformer完成的。例如,创建Deployment的控制器的核心代码如下:
kubeInformerFactory := kubeinformers.NewSharedInformerFactory(kubeClient, resyncPeriod)
deploymentInformer := kubeInformerFactory.Apps().V1().Deployments()
deploymentInformer.Informer().AddEventHandler(cache.ResourceEventHandlerFuncs{
AddFunc: controller.handleObject,
UpdateFunc: func(old, new interface{}) {
newDepl := new.(*appsv1.Deployment)
oldDepl := old.(*appsv1.Deployment)
if newDepl.ResourceVersion == oldDepl.ResourceVersion {
return
}
controller.handleObject(new)
},
DeleteFunc: controller.handleObject,
})
kubeInformerFactory.Start(stopCh)
具体地,如图1-7所示,SharedInformer有Reflector、Informer、Indexer和Thread Safe Store四个组件。

Reflector用于监听特定的Kubernetes API资源对象,可以是Kubernetes内建的或者是自定义的资源。其具体实现是通过ListAndWatch的方法进行的。首先,Reflector将资源版本号设置为0,使用List操作获得指定资源对象,这可能会导致本地的缓存相对于etcd里面的内容存在延迟。然后,Reflector通过Watch操作监听到API Server处资源对象的版本号变化,并将最新的数据放入Delta FIFO队列中,使得本地的缓存数据与etcd的数据保持一致。如果resyncPeriod不为零,那么Reflector会以resyncPeriod为周期定期执行Delta FIFO的Resync函数,这样就可以使Informer定期处理所有的对象。
Informer的内部机制是从Delta FIFO队列中弹出对象,一方面将对象存入本地存储以供检索,另一方面触发事件以调用资源事件回调函数。控制器后续的典型模式是获取资源对象的key,并将该key排入工作队列以进一步处理。Indexer提供对象的索引功能。
Indexer可以根据多个索引函数维护索引。Indexer使用线程安全的数据存储来存储对象及其键。在Store中定义了一个名为MetaNamespaceKeyFunc的默认函数,该函数生成对象的键的格式是/的组合。
目 录
第1章 架构基础 1
1.1 云计算的变革 3
1.1.1 物理机时代 3
1.1.2 虚拟化时代 4
1.1.3 容器化时代 6
1.2 Kubernetes模型设计 11
1.2.1 对象的通用设计原则 11
1.2.2 模型设计 12
1.2.3 核心对象概览 16
1.2.4 控制器模式 20
1.2.5 控制器的协同工作原理 23
1.3 Kubernetes核心架构 25
1.3.1 核心控制平面组件 26
1.3.2 工作节点控制平面组件 33
1.3.3 Pod详解 43
第2章 计算节点管理 52
2.1 操作系统 55
2.2 文件系统规划 57
2.3 容器核心技术 58
2.3.1 Namespace 59
2.3.2 Cgroups 64
2.3.3 容器运行时 71
2.3.4 容器存储驱动 77
2.4 节点资源管理 82
2.4.1 状态上报 82
2.4.2 资源预留 83
2.4.3 驱逐管理 84
2.4.4 容器和系统资源配置 87
2.5 存储方案 99
2.5.1 存储卷插件管理 99
2.5.2 存储的分类 102
2.6 节点调优 114
2.6.1 NUMA架构 114
2.6.2 CPU性能 115
2.6.3 内存 117
2.6.4 磁盘 120
2.6.5 网络性能 121
第3章 构建高可用集群 138
3.1 高可用的常用手段 141
3.2 Kubernetes高可用层级 144
3.3 控制平面的高可用保证 148
3.3.1 etcd高可用保证 149
3.3.2 API Server高可用保证 156
3.3.3 控制器高可用保证 164
3.3.4 集群的安全性保证 165
3.4 面向应用的高可用特性 173
3.5 模型驱动的集群搭建与管理 176
第4章 构建企业级镜像仓库 184
4.1 镜像仓库综述 185
4.1.1 镜像仓库 185
4.1.2 镜像管理 187
4.2 企业级镜像仓库 189
4.2.1 架构总览 191
4.2.2 数据库 193
4.2.3 块存储 194
4.2.4 镜像仓库实例部署 195
4.3 镜像仓库缓存 196
4.3.1 镜像分发的挑战 196
4.3.2 镜像缓存服务拓扑 198
4.3.3 镜像缓存流量管理 199
4.3.4 高可用镜像缓存服务 199
4.4 镜像安全 200
4.4.1 镜像扫描 201
4.4.2 镜像策略准入控制 206
4.4.3 镜像安全监控 210
第5章 多租户生产集群 213
5.1 租户 214
5.1.1 多租户支持 214
5.1.2 Kubernetes多租户有限支持 216
5.1.3 Kubernetes租户扩展 218
5.2 认证 222
5.2.1 Kubernetes认证 222
5.2.2 用户认证 225
5.2.3 高负载认证实践 227
5.3 授权 229
5.3.1 Kubernetes授权 230
5.3.2 租户授权 235
5.3.3 特殊权限管理 236
5.3.4 特殊权限应用 238
5.4 隔离 243
5.4.1 节点隔离 244
5.4.2 容器隔离 247
5.4.3 网络策略隔离 249
5.5 配额 252
5.5.1 Kubernetes配额 252
5.5.2 高阶配额 255
5.5.3 租户配额 262
5.5.4 租户配额实践 265
第6章 网络接入方案 267
6.1 数据中心基础架构 268
6.2 域名服务 270
6.3 Linux网络基础 273
6.3.1 理解Linux网络协议栈工作机制 273
6.3.2 iptables 275
6.3.3 ipset 277
6.3.4 IPVS 278
6.4 负载均衡 280
6.4.1 负载均衡的实现机制 281
6.4.2 负载均衡的技术实现 283
6.4.3 负载均衡的部署模式 288
6.4.4 负载均衡策略 289
6.4.5 健康检查 291
6.5 Kubernetes中的服务发布 291
6.5.1 创建服务 293
6.5.2 服务的类型 296
6.5.3 基于kube-proxy实现的流量转发 300
6.5.4 Service高级特性 308
6.6 DNS 312
第7章 API网关和服务网格 315
7.1 API网关 316
7.2 服务网格 320
7.3 深入了解Envoy 322
7.3.1 Envoy发现机制 325
7.3.2 Envoy架构 330
7.4 Ingress 334
7.4.1 功能概述 334
7.4.2 Ingress的挑战 336
7.5 Contour 337
7.5.1 架构 338
7.5.2 高级功能 341
7.6 Istio 350
7.6.1 架构 350
7.6.2 Sidecar 353
7.6.3 Ingress网关 360
7.6.4 金丝雀发布和流量灰度 363
7.6.5 安全保证 365
7.6.6 策略管理和遥测 368
7.6.7 数据平面加速 371
7.6.8 优势和挑战 372
第8章 集群联邦 374
8.1 集群联邦概览 377
8.1.1 集群联邦设计 377
8.1.2 集群注册中心 379
8.1.3 联邦共享逻辑 380
8.1.4 联邦类型配置 384
8.1.5 同步控制器 385
8.1.6 副本调度控制器 386
8.1.7 全局DNS服务 388
8.2 定义联邦资源 390
8.2.1 集群资源 390
8.2.2 联邦资源 391
8.2.3 定义联邦资源 393
8.2.4 联邦资源管理 397
8.3 联邦应用 398
8.3.1 联邦应用 400
8.3.2 联邦应用部署 401
8.3.3 联邦应用运维 402
8.3.4 集群联邦的局限性与解决方案 409
第9章 边缘计算 416
9.1 边缘数据中心 417
9.1.1 智能域名服务(GSLB) 418
9.1.2 边缘网络接入 420
9.1.3 规划边缘计算应用 428
9.2 KubeEdge 430
9.2.1 通信协议 432
9.2.2 CloudCore 440
9.2.3 EdgeCore 446
9.2.4 设备映射器 450
9.2.5 未来展望 455
第10章 应用落地 456
10.1 应用容器化 459
10.1.1 Dockerfile 459
10.1.2 容器化带来的影响 463
10.2 应用接入的最佳实践 466
10.2.1 资源定义 466
10.2.2 灵活定义Pod 468
10.2.3 应用配置 473
10.3 应用管理 477
10.3.1 无状态应用 477
10.3.2 有状态应用 480
10.3.3 Operator 483
10.4 集群应用运维 485
第11章 监控和自动修复 488
11.1 指标监控系统 490
11.1.1 监控系统的构建 491
11.1.2 Prometheus Operator 499
11.2 日志管理系统 501
11.3 关键指标定义 503
11.4 自动修复系统 505
11.4.1 Node Problem Detector 505
11.4.2 自动修复控制器 508
11.5 事件监控系统 509
11.6 状态监控系统 511
第12章 DEVOPS 513
12.1 拥抱DevOps 515
12.2 自治跨职能团队 520
12.3 敏捷开发 523
12.4 GitOps 529
12.5 质量保证 533



















云原生代表了新一代的技术方向,所有开发者都需要关注云原生的发展。作为Kubernetes的早期实践者之一,eBay完成了大数据、搜索后台、云业务等支撑平台基于Kubernetes的归一,书中融入了不少实用的生产实践,十分具有借鉴意义。作者不拘泥于陈列代码,尝试思考和解读Kubernetes的设计精髓,简洁明了,非常适合进阶学习。
王泽锋
CNCF TOC贡献者、KubeEdge和Volcano项目联合创始人
华为云原生开源负责人
市面上讲解Kubernetes的书不在少数,但是本书完全站在企业级落地实践的视角,来深入阐述Kubernetes生产化实践过程中所遇到的挑战及对应的解决方案,所有案例都来自eBay的一线实践。相比其他讲解Kubernetes的入门书籍而言,本书具有更好的实战参考价值,可以说本书是大型软件企业实现Kubernetes“躬身入局”的必读佳作。
茹炳晟
腾讯TEG 基础架构部 资深技术专家
腾讯云*具价值专家 TVP